This approach makes it possible to inline more information about the related resource without having to change the structure of the response or introduce more top-level response fields.
面向领域实体及关系的范式化(normalized)API 设计风格
本文创作于 2015-06-06
背景
很多年以前,大多数的 Web 开发是在开发网页应用,基本流程是解析参数、获取数据、渲染模版。市面上几乎每一款 Full Stack Web 框架都基于 MVC 架构,Controllers 将处理好的 Models 交给 Views 来渲染。进入移动时代后,随着网页应用转为 App,MVC 中的 V 不见了, 后端不再需要渲染模版了,UI 和交互全部都由 App 采用 Native 的方式来实现,而数据则通过 API 的方式从服务器传到客户端 App。Web 开发也慢慢地由网页应用开发转变为 API 开发。
『罗马不是一天建成的』,API 的设计从一开始就受到了 MVC 架构的影响,很多 API 的设计都是参考了 MVC 中『Controllers 将处理好的 Models 交给 Views 处理成 Templates 需要的结构』的设计,只是不再是『将数据传给 Templates』而是通过 API 将数据传给 App。
这种 API 设计非常常见,我们将之称为『套模板』式 API 设计。一般的场景是服务端和客户端的研发同事一起照着 PM 给的页面原型图在一个僻静的会议室里一起设计 API。
嵌套外键关系
随着业务的复杂度不断增加,客户端程序也需要处理大量的业务逻辑,已经不再是一系列 Native 的 Templates 了。客户端程序也开始有了自己的 MVC 架构,引入了 Models 层,增加了领域实体对象的持久化。此时,客户端对 API 的要求不再是局限于『套模板』了,而是需要 API 返回领域实体的对象数据。API 设计风格不断地演化,逐渐形成了一些约定和要求。其中,最有名的要数『嵌套外键关系』了,譬如:Nest foreign key relations。
NoSQL 数据库 mongodb 提出了文档型数据库的概念,在日常工作中,我们使用 mongodb 存储数据的方式与『嵌套外键关系』的 API 设计非常相似。它们都提倡所表现的数据在语义上自包含的,对人类而言更自然和简单,表现力更强大,易懂。
HTTP API Design Guide 中提到的一个好处是:
在不引入新的顶级字段或不调整返回结构的情况下内敛更多的关联数据。
Example 1. 一个『嵌套外键关系』设计风格的例子
{
"tweets": {
"id": 20000000,
"content": "这是一条微博",
"create_time": "2015-07-17 08:09:03",
"images": [],
"user": {
"id": 100000001,
"name": "张三",
"avatar_url": "http://touxiao/zhangsan"
},
"comments": [{
"id": 30000001,
"content": "好微博",
"create_time": "2015-07-17 08:09:03",
"user": {
"id": 100000001,
"name": "张三",
"avatar_url": "http://touxiao/zhangsan"
}
}]
}
}遇到的问题
没有银弹的设计。
『嵌套外键关系』的 API 设计也存在一些问题。我们分别从客户端和服务端的角度来分析这种 API 设计所带来的弊端。
客户端
客户端想通过 API 从服务端获取什么数据?领域实体对象!马丁福勒在《企业应用架构模式》一书中提到了一种名为『Identity Map[1]』的模式,『Ensures that each object gets loaded only once by keeping every loaded object in a map. Looks up objects using the map when referring to them』。它解决的问题是:『a man with two watches never knows what time it is』。
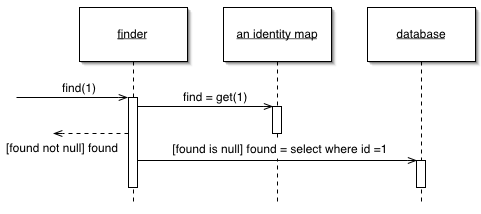
Figure 1. Identity Map 模式
事实上,我们的客户端程序面临着同样的问题。『嵌套外键关系』的 API 设计会导致同一条记录被加载到多个对象中。当其中一个对象被修改时,其他的对象不会得到应有的更改,这样可能会导致一些奇怪的错误和问题,譬如在 A 页面展示数字是 1,而 B 页面展示的数字是 0。
不仅如此,解析 API 的工作也非常不容易。一种类型的对象可能需要从被嵌套的数据中解析出来,也可能不需要,还可能被从多种不同对象的嵌套数据中解析。为每一个 API 实现一个解析函数是一件很平常的事情。
服务端
在开发 API 的过程中,有很大一部分工作是处理输出结果的结构,也就是我们常说的对象序列化过程,俗称『打包』。『嵌套外键关系』的 API 设计风格使对象的序列化耦合在一起,例如,订单对象嵌套有用户对象,那么在序列化订单对象的时候,必须也要把对应的用户对象一起序列化。这会导致『打包』的逻辑非常复杂,甚至极端情况下,还会出现循环嵌套的情况(A 嵌套 B,B 又嵌套 A)。另外,还需要结合每个 API 输出结果的实际情况,返回不同的内容;若再考虑上版本的变化,这个过程将更加复杂。
范式化 API 设计风格
范式化(normalization)即正规化、标准化。数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁、结构明晰的,减少数据的冗余,增进数据的一致性。[2]
范式化模型要求满足下面三大范式:
-
每个字段只包含最小的信息属性。如果某个字段名称为 name-age,value 为 zhangsan-23,则这个模型不满足第一范式,需要将 name-age 分为两个属性 name 和 age 后才满足第一范式。
-
(在满足第一范式基础上)模型含有主键,非主键字段依赖主键。比如订单这个模型,它的主键是订单 ID,那么订单模型其它字段都应该依赖于订单 ID,如商品 ID 和订单没有直接关系,则这个属性不应该放到订单模型而应该放到 "订单 - 商品" 中间表。
-
(在满足第二范式基础上)模型非主键字段不能相互依赖。订单表 (订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列 "订单编号" 相关,再细看你会发现 "顾客姓名" 和 "顾客编号" 相关,"顾客编号" 和 "订单编号" 又相关,最后经过传递依赖,"顾客姓名" 也和 "订单编号" 相关。为了满足第三范式,应去掉 "顾客姓名" 列,放入客户表中。
『Identity Map』模式本身就是范式化的一种表现,所有的领域实体对象按照特定的结构来组织,以『标识域』[3]为 key 来存储到 Map 容器当中。它们和数据库范式的区别就是一个是用来管理和维护内存中的领域实体对象,一个是用来规范数据库的表结构关系。
本文主要讨论的是内存中的领域实体对象的组织和管理,因此我们先回到『Identity Map』模式本身,一种常见的设计是采用多层 Map 来实现,下面的代码阐述了这种数据结构的设计。
Example 2. 一种常见的『Identity Map』的组织结构
{
"users": {
"1": {
"id": 1,
"name": "用户名"
}
},
"orders": {
"1": {
"id": 1,
"user_id": 1
}
}
}上述结构展示用户和订单。
第一层 Map 是领域实体的名称,采用小写复数形式表示。第二层则用来存储该类型的领域实体对象,以对象的『标识域』(上例为 id)的值为 key,对象本身为 value。
我们会发现『Identity Map』的领域实体对象的关系组织方式与『嵌套外键关系』的设计风格是有显著区别的,这就是『范式化的设计风格』。
改造客户端 Models 层架构
如之前所述,引入『Identity Map』模式对客户端的 Models 层的架构有显著的帮助。下图展示了引入了『Identity Map』、『数据访问对象』等模式后,客户端访问一个领域实体对象的时序图。

Figure 2. 客户端访问一个领域实体对象的时序图
改造后所有的领域实体记录只有一个实例对象,它们由 Identity Map 组织并管理,Identity Map 组件负责将数据持久化到本地的数据库(一般是 SQLite)中。对象从 API 获得之后,首先要更新到 Identity Map,在进行清洗合并之后,返回给应用程序使用。
难道 API 是为 Identity Map 服务的?
You’ve got the point!
API 肯定是要为 Identity Map 服务,它是 Identity Map 的数据来源,API 70% 的职责就是在这儿。由于 API 可能非常多,功能非常杂,因此,将 API 返回的对象清洗并合并到 Identity Map 这项工作是非常繁琐和复杂的。
我们应该通过调整 API 的设计风格来降低这些工作的复杂度。于是,基于范式化的 API 设计风格自然而然地出现在所有方案的第一条。
|
Note
|
当两个模块的数据结构趋于一致时,这两个模块的通信将会非常简单。 |
优缺点
第一个优点可以显著地降低程序处理领域实体对象序列化(服务端)/反序列化(客户端)时的复杂度。当所有的 API 中领域实体对象的组织结构都一致了,不再随着返回内容的不同而有变化,那处理或解析这些对象的模块就可以统一。
Example 3. 服务端处理领域实体对象序列化的例子
Python 语言 json 模块提供的 dumps 方法中,提供了一个参数:default,它接收一个 function 对象,输入为需要序列化的对象 obj,输出为一个可序列化的对象,通常是 dict。
假设我们的领域实体对象都继承自 Entity 类,那我们可以提供一个如下的一个函数:
def json_default(obj):
if isinstance(obj, Entity):
return obj.to_dict()
return obj这样,打包任何实体对象的时候都不需要载入其他的对象,打包过程完成是自包含的,没有任何耦合的。事实上,在基于范式化的 API 设计风格下,『打包』这个过程已经非常淡化了,实体自带『打包』黑科技。
客户端反序列化对象的过程和服务端类似,基本出发点都是在统一的模块中集中处理。
第二个优点应该和『Identity Map』这种模式的优点类似,API 反映的实体记录明确且唯一,不会出现不一致甚至字段不统一的情况。性能高,重复的记录只会在 API 中出现一次。
|
Warning
|
缺点
与『嵌套外键关系』的设计风格相比,范式化的 API 设计风格最大的缺点就是不自然、人类不方便阅读 API 的内容。这个问题对一些需要向第三方提供 API 服务的开发平台来说比较重要。普通的自用 API 这个问题会相对小一些。
|
深入讨论
API 的版本
移动客户端的升级是移动时代 API 设计面临比较多的问题之一,Web 2.0 时代,渲染等工作都是浏览器完成的,版本的概念很淡,一旦新版本上线,旧版本就成为历史,不复存在了。
但是客户端的升级与浏览器端的应用升级完全不一样,虽然各大手机厂商想尽办法提高用户升级的比例,但升级依然是一个漫长且痛苦的过程。反映到 API 的设计上,即:API 需要考虑版本的问题。
关于 API 版本的讨论,可以参考我之前发表的另一篇博文《浅谈 API 版本》,我们这儿只讨论范式化 API 设计风格如何简化服务端程序的复杂度。
我们在上面提到的 Python json.dumps 的例子展示,当引入了 API 的版本的时候,不同版本的实体的序列化结果是不一样,因此,to_dict 需要加入 version 参数,例如:User 对象在 version=1 时不返回 city_id 字段,在 version>=2 的时候才会返回 city_id 字段,因为 version=1 的时候还没有城市这个功能。
|
Note
|
大多数情况下,加字段对客户端程序不会造成任何影响。因此,单纯加字段不建议升级 API 的版本。 |
from flask import request
def json_default(obj):
# Flask 的 request 是一个全局代理对象
version = get_api_version(request)
if isinstance(obj, Entity):
return obj.to_dict(version)
return obj在『嵌套外键关系』设计风格下,这个事情就比较难办了,你可能需要先根据版本号来确定是否把用户所关联的 city 对象加载并一同传给打包模块。
实体的数据结构在服务端与客户端的差异
以用户头像为例,假设我们的用户头像是存储在 CDN 上,CDN 有多个域名,我们希望客户端按一定的规则从 CDN 获取用户头像,假设某个 CDN 获取头像失败了,客户端还可以从其他的 CDN 获取头像。
|
Note
|
CDN 的域名会随着供应商的变化而变化。 |
此时,在服务端,用户对象的数据结构表示头像的字段为 avatar_uri,表示域名无关的地址。而客户端希望的数据结构是一个 list,依次返回目前正在使用的 CDN 地址列表,如:avatar_urls: ["url1", "url2"]。
这个转换过程可以在对实体序列化中完成。
|
Note
|
这种转换只能是实体自包含或者配置依赖。 |
领域实体其他关系的组织
这就是全部么?
当然不是,上面提到,这只是 API 工作的 70%,还有 30% 呢!『Identity Map』模式解决的问题是实体自身的组织方式及外键关系的组织。但是,实体直接的关系不仅仅局限于『BelongsTo/HasOne』这一种关系。常见的有 OneToOne、OneToMany、ManyToMany等等。
关于其他实体关系的组织,不禁让我想起了关系型数据库及其 SQL 语言强大的表现能力,譬如:要查询我的订单,只要 SELECT * FROM orders WHERE user_id=1 就可以了。而这种关系要体现在 API 中就不是那么简单了。
一种常见的设计是 RESTful + 『嵌套外键关系』,如返回用户 1 的订单:
Example 4. HasMany 关系的设计
URL
/users/1/orders/?count=2
返回结果
[{
"id": 1,
"user": {
"id": 1,
"name": "用户"
},
"product": {
"id": 1,
"name": "产品1"
},
"count": 20
}, {
"id": 1,
"user": {
"id": 1,
"name": "用户"
},
"product": {
"id": 2,
"name": "产品2"
},
"count": 20
}]反范式
对,反范式!
这儿我们借鉴一下缓存的设计,假设如果要你构建一个数据结构,来实现加速查询某个用户的订单的需求,通常的设计是:
{
"user_orders": { // 用户 ID => [订单 ID 列表]
"1": [1, 2, 3],
"2": [4, 5, 6]
}
}结合上面范式化 API 设计,那这个 API 的结构是:
{
"entities": {
"users": {
"1": {...},
"2": {...}
},
"orders": {
"1": {...},
"2": {...}
...
}
}
"user_orders": { // 用户 ID => [订单 ID 列表]
"1": [1, 2, 3],
"2": [4, 5, 6]
}
}虽然这里面可能出现数据一致性的问题,譬如:user_orders 与 orders 的 user_id 可能因为某些错误产生冲突的,但选用的数据结构是最合适的。
Flux/Redux && Immutable
2014年,Facebook 提出了单向数据流的概念,开源了 Flux 框架。次年,Redux 框架诞生,这两个框架在 Github 上砍下了数万的 Stars。单向数据流的一个核心概念就是数据的变更驱动程序行为,所有的 Action 均有 Store 的变化发起。数据对象 Immutable 后会更方便发现变更行为。
之所以提到 Flux/Redux 并不是要介绍它们,而是我在研究后会发现,Store(主要是 Redux 的 Store,我没用过 Flux)其实就是 Identity Map 组件以及存储其他实体对象关系的地方,而且 Redux 官方文档里也建议在 Store 采用范式来存储实体对象[4]。
|
Note
|
采用 Redux/Flux 框架的 WebApp 也应该采用面向领域实体及关系的范式化 API 设计风格 |
Main Point
-
本文阐述了一种使用面向领域实体及关系的范式化 API 设计风格;
-
它是由『嵌套外键关系』的 API 设计风格发展而来的;
-
其背后对应的模式是『Identity Map』;
-
改造客户端程序的 Models 层,引入了
Identity Map组件 ,采用范式化 API 设计风格可以显著的降低程序的复杂度。范式化 API 设计风格也可以使服务端程序序列化模块的复杂度显著降低,API 也更高效。但是它也有一些缺点; -
在某些领域实体关系的处理上,需要一些反范式的思想,可以借鉴缓存类数据结构的设计。
-
所有 API 都需要这种设计。